GCC, Clang and MSVC are powerful compilers, with many heuristics to emit the most efficient instructions, maybe even optimal ones. The same goes for ICC, a.k.a Intel’s compiler, well known for outranking all the others regarding the performance of the generated code. We rarely talk about it but it is here. (By the way, did you know that Intel is migrating his compiler to LLVM? The new compiler’s name is ICX for the C language, and ICPX for C++).
It is quite difficult nowadays to outperform these compilers with hand-written assembly. Let’s check for example this algorithm to search an integer value in an array:
// Returns the index of the first occurrence of k in the n integers
// pointed by v, or n if k is not in v.
size_t find_int_c(int k, const int* v, size_t n)
{
for (size_t i = 0; i != n; ++i)
if (v[i] == k)
return i;
return n;
}
Simple and straightforward, a good old algorithm written in C. Let’s see how the compilers perform. In order to compare them, I use Google Benchmark to measure the time spent to search the last entry for an array of distinct values (i.e. this is the worst case scenario), for input sizes up to 16 million entries. The computer running the program is a MacBook Pro from around 2012, with a 4-cores i5–3210M at 2.5 GHz and 8 GB of 1600 MHz DDR3L SDRAM. The operating system is Ubuntu 21.04 with GCC in version 11.1, Clang version 12, ICC and ICPX version 2021.3.0. The tests are — obviously — compiled with -O3 and -DNDEBUG.
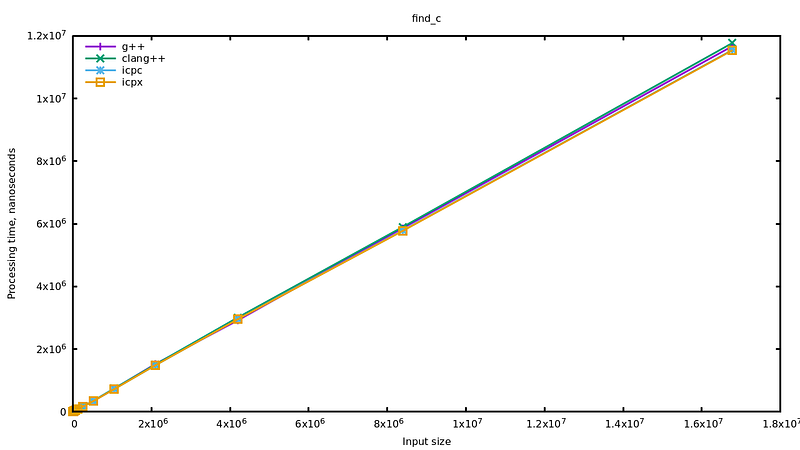 Without any surprise, the compilers are equally efficient. Also, it should be noted that the algorithm is not very complex, one could suppose that the optimization heuristics are doing their job. Anyway, we are in 2021 and you are certainly thinking something along the lines of “why the heck are you writing a loop? What are you, a programmer?”. Well, let’s hide this loop with an algorithm taken straight from the STL:
Without any surprise, the compilers are equally efficient. Also, it should be noted that the algorithm is not very complex, one could suppose that the optimization heuristics are doing their job. Anyway, we are in 2021 and you are certainly thinking something along the lines of “why the heck are you writing a loop? What are you, a programmer?”. Well, let’s hide this loop with an algorithm taken straight from the STL:
// Returns the index of the first occurrence of k in the n integers
// pointed by v, or n if k is not in v.
size_t find_int_cpp(int k, const int* v, size_t n)
{
return std::find(v, v + n, k) — v;
}
I will skip the ranges version from even more moderner C++20 because it does not make a difference in the compiled binary. Let’s just note that the simple change of passing –std=c++20 to the compiler has multiplied the compilation duration by 1.55 (on a basis of 1.35 seconds in C++11), versus a factor of 1.17 for C++17 and 1.02 for C++14. Moreover, neither ICPC nor ICPX 2021 can handle C++20.
I launch the benchmark with this change but one can guess that it won’t make a difference against the original algorithm.
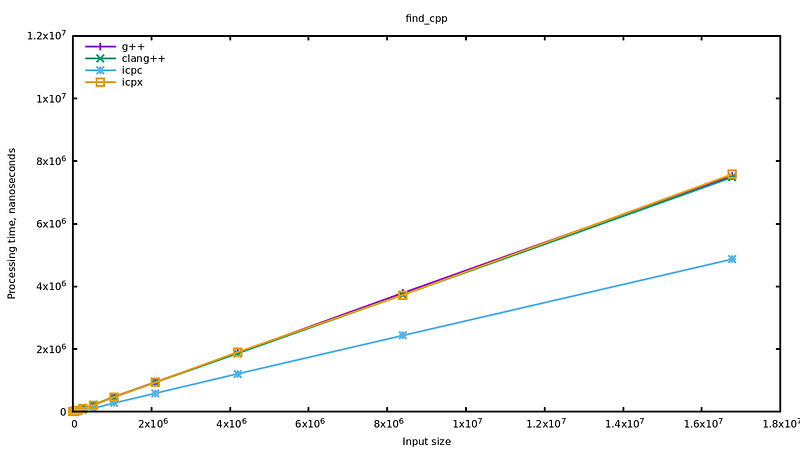 Well… Ahem… It was unexpected.
Well… Ahem… It was unexpected.
There are two things to see here: first of all, everything is very much faster than with the C-loop (notice that the range on the y-axis has not changed), then, secondly, the implementation from ICPC is even more faster that the others. We are talking about a decrease of the execution time by 35–40% for the former, and 70–75% for ICPC.
With a dumb loop like that, we can easily guess that the compiler is using a good old loop-unrolling technique. Let’s confirm for example by testing eight entries per iteration:
// Returns the index of the first occurrence of k in the n integers
// pointed by v, or n if k is not in v.
size_t find_int_c_unrolled_8(int k, const int* v, size_t n)
{
size_t i = 0;
for (; n - i >= 8; i += 8)
{
if (v[i] == k)
return i;
if (v[i + 1] == k)
return i + 1;
if (v[i + 2] == k)
return i + 2;
if (v[i + 3] == k)
return i + 3;
if (v[i + 4] == k)
return i + 4;
if (v[i + 5] == k)
return i + 5;
if (v[i + 6] == k)
return i + 6;
if (v[i + 7] == k)
return i + 7;
}
for (; i != n; ++i)
if (v[i] == k)
return i;
return n;
}
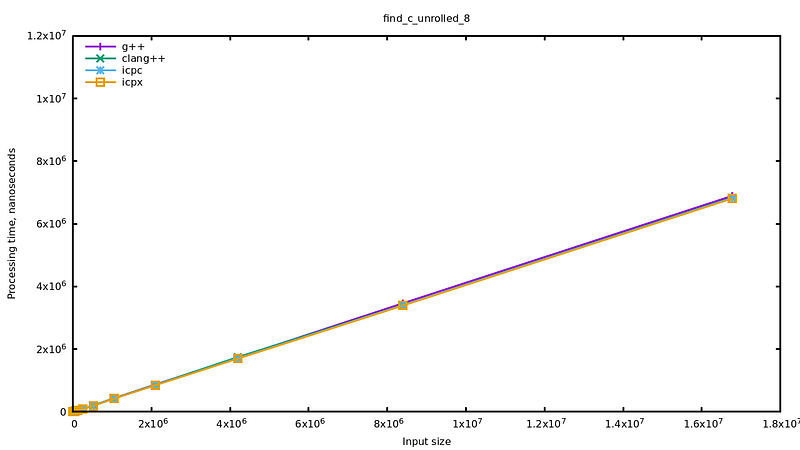 It seems equivalent, even though it looks faster than the implementation from std::find(). Actually we can directly check in the source from libstdc++ and observe that they process four entries at each iteration. Another remarkable point is also that ICPC is back in line, equivalent to the others, which means that there is something special in std::find() with it.
It seems equivalent, even though it looks faster than the implementation from std::find(). Actually we can directly check in the source from libstdc++ and observe that they process four entries at each iteration. Another remarkable point is also that ICPC is back in line, equivalent to the others, which means that there is something special in std::find() with it.
Interestingly, ICC has no STL of its own and uses the one from GCC, which means that it can produce a better binary from the code than the compiler for which this code was explicitly written. Funny isn’t it?
Now can you guess what is the particularity of the implementation resulting from the use of ICC? Turn your screen upside down to check your answer: suoᴉʇɔnɹʇsuᴉ ꓷWIS sǝsn ꓛꓒꓛI ɯoɹɟ uoᴉʇɔunɟ ()puᴉɟ::pʇs ǝɥꓕ. I have obviously no access to the source of ICPC to confirm this claim, so I present you this implementation with SSE2 instructions:
// Returns the index of the first occurrence of k in the n integers
// pointed by v, or n if k is not in v.
size_t find_int_sse2(int k, const int* v, size_t n)
{
// We are going to check the integers from v four by four.
// This instruction copies the searched value k in each of the
// four 32-bits lanes of the 128 bits register. If k…k represents
// the 32 bits of k, the register then looks like this:
//
// [ k…k | k…k | k…k | k…k ]
//
const __m128i needle = _mm_set1_epi32(k);
// Here we just reinterpret the pointer v as a pointer to 128 bits
// vectors. This will allow to access the integers four by four.
// And yes, I do use a C cast like a barbarian.
const __m128i* p = (const __m128i*)v;
// A division! Will the compiler emit a shift for it?
const size_t iterations = n / 4;
const size_t tail = n % 4;
for (size_t i(0); i != iterations; ++i, ++p)
{
const __m128i haystack = *p;
// This compares all four 32 bits values of needle (so four
// times the searched value) with four integers pointed by p,
// all at once. All bits of a 32 bits lane are set to 1 if the
// values are equal. The operation looks like this:
//
// [ k…k | k…k | k…k | k…k ]
// cmpeq [ a…a | b…b | k…k | c…c ]
// = [ 0…0 | 0…0 | 1…1 | 0…0 ]
//
const __m128i mask = _mm_cmpeq_epi32(needle, haystack);
// We cannot compare mask against zero directly but we have an
// instruction to help us check the bits in mask.
// This instruction takes the most significant bit of each of
// the sixteen 8 bits lanes from a 128 bits register and put
// them in the low bits of a 32 bits integer.
//
// Consequently, since there are four 8-bits lanes in an
// integer, if k has been found in haystack we should have a
// 0b1111 in eq. Otherwise eq will be zero. For example:
//
// movemask [ 0…0 | 0…0 | 1…1 | 0…0 ]
// = 0000 0000 0000 0000 0000 0000 1111 0000
//
const uint32_t eq = _mm_movemask_epi8(mask);
// Since we are back with a scalar value, we can test it
// directly.
if (eq == 0)
continue;
// Now we just have to find the offset of the lowest bit set
// to 1. My laptop does not support the tzcnt instruction so I
// use the GCC builtin equivalent.
const unsigned zero_bits_count = __builtin_ctz(eq);
// Each 4 bits group in eq matches a 32 bits value from mask,
// thus we divide by 4.
return i * 4 + zero_bits_count / 4;
}
// Handle the last entries if the number of entries was not a
// multiple of four.
for (size_t i(iterations * 4); i != n; ++i)
if (v[i] == k)
return i;
return n;
}
Time to do the measures:
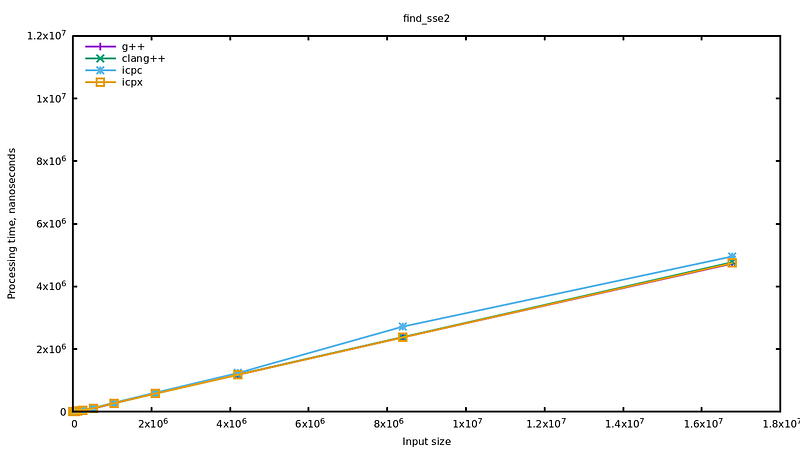 And voilà, now all the tested compilers generate a program on par with the implementation of std::find() resulting from ICPC. At least it seems so on the graphs, where we can mostly see the large inputs.
And voilà, now all the tested compilers generate a program on par with the implementation of std::find() resulting from ICPC. At least it seems so on the graphs, where we can mostly see the large inputs.
Vectorized code sometimes has some warm up cost, making it less efficient when the input is small. Let’s look if we have the problem here by switching to a logarithmic scale on the x-axis. In the graphs below, one for each compiler, the lines show the performance of each implementation relatively to the C code.
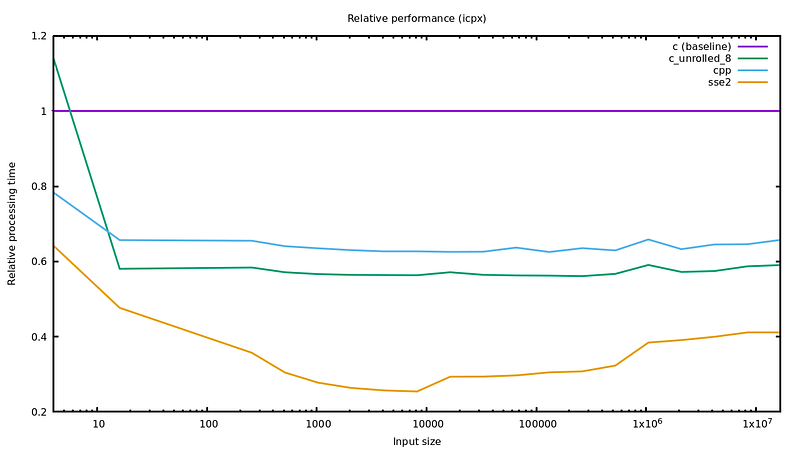 Relative algorithm performance with ICPX, baseline is the C-loop.
As you can see, the SSE2 implementation is always faster than the C version, and better than the std::find() version except for ICPC with input arrays larger than 256 entries. I did not look into the details here but my guess is that if the binary produced by ICC is generated from GCC’s libstdc++ code, then it has both loop-unrolling and vectorization. Actually I observed that the results obtained with GCC could be improved with a #pragma GCC unroll 4 before the main loop, suggesting it could be the right track.
Relative algorithm performance with ICPX, baseline is the C-loop.
As you can see, the SSE2 implementation is always faster than the C version, and better than the std::find() version except for ICPC with input arrays larger than 256 entries. I did not look into the details here but my guess is that if the binary produced by ICC is generated from GCC’s libstdc++ code, then it has both loop-unrolling and vectorization. Actually I observed that the results obtained with GCC could be improved with a #pragma GCC unroll 4 before the main loop, suggesting it could be the right track.
Want more? Feel free to checkout the benchmark and play around.
Personal Thoughts
This journey was quite entertaining actually. It began as I was getting my hands on intrinsics, trying to validate my implementation — both in terms of computations than in efficiency — with the binary produced by GCC for the C-loop. What a surprise to see my code computing the result four times faster!
Thinking about it there is some bittersweetness in these results. For the last twenty years I have heard so many times that engineering time is expensive and that we should rather buy more CPUs and memory, that Moore’s law will do the rest. During the same period I saw the same message repeated too often, that “today’s” compilers are efficient, etc. Only to finally discover that only a single compiler on the four tested ones actually outputs optimized code. Worse, if I use the most recent compiler from this editor, i.e. ICPX versus ICPC, then I lose this optimization! There, allow me to quote Intel’s announcement:
The latest Intel C/C++ compilers, using LLVM, deliver faster compiler times, better optimizations, enhanced standards support, and support for GPU and FPGA offloading.
Better.
Optimizations.
More and more these days, I find myself thinking that those who adopt this narrative (“today’s compilers are very efficient etc.”) just don’t want to check how their code is translated into machine code, then repeat this doctrine to avoid having to think about it.
It is obviously not about optimizing everything, but the actual reason why we write high-level code is not because compilers are efficient; it is rather about a compromise for delivery time. In other words, we accept suboptimal code in favor of a simplified writing and maintenance.
By the way, I am also a bit disappointed to see that the diversity of compilers is slowly decreasing toward a single model, LLVM. I feel like reliving the Chrome effect: initially it is fresh, young and efficient, it boosts the ancestor (Firefox/GCC); then it keeps becoming larger and larger, it eats everything, and the concept of choice disappears (Internet Explorer is dead, the Chromium-based Edge replaces it, and every modern application uses Electron; while every modern compiler uses LLVM).
I am not saying that LLVM is as problematic as Chrome, there are many nice tools coming from LLVM (clang-format, clang-tidy, FileCheck…), but I doubt it is a good-enough reason to get rid of any diversity, personality, creativity, and end up with a single model.
As a small counter measure for this and to stay positive, I incite you to put to the test the tools you use, to compare them to other tools and also to what you can do by yourself. In the end the decision will probably still be “meh let’s just use X, it is worse but everybody uses it and it will be quickly integrated”, because when there is money or popularity at risk, the only thing that counts is the productivity. But maybe if we start to focus on the details we will slowly and surreptitiously push a culture of curiosity, of challenge and optimization. Even if nothing changes, we will still learn new things, and this is a good thing :)