Table of contents
This is the fifth and last post in the series about effortless performance improvements in C++. Check the first post to get the full story!
Last
time
we replaced almost all uses of std::string with std::string_view
and we also dropped the input/output libraries for ad-hoc parsing. The
combined impact of these changes is in the order of 27 to 47%
performance improvements. After these changes, the only function we
did not touch in the top five bottlenecks was replace, where the
time is mostly spent in calls to std::string::find. It’s time to
look into it. As you will see, it is a bit more complex than switching
one type for another.
Contrary to the previous posts, there is no easy solution here. No “replace this type by this one” nor “just call this functions”. We are thus going into what I would qualify as a second step in this optimization journey: refocusing on our needs.
After having improved the replace function, we will also talk about
the benefits we can get from third-party dependencies compared with
the standard library. Even though the operation seems simple, I
consider the introduction of such dependencies to have a hidden
maintenance cost, so it must not be done lightly. We will discuss that
below.
For now, it’s time to go…
Back to the specs
Before we try to optimize our replace function, we must understand
the service it provides and why we need it. Our current implementation
looks like this:
void replace(std::string& s, const char* from, const char* to)
{
std::size_t pos = 0;
while ((pos = s.find(from, pos)) != std::string::npos)
{
s.replace(pos, std::strlen(from), to);
pos += std::strlen(to);
}
}
The function is quite trivial and there is no obvious problem. No
useless use of std::string here, maybe some unnecessary calls to
strlen in the loop? Since the from and to arguments do not
change, the results of the calls to strlen are invariants in this
loop. Also, there may be a hidden strlen in s.find to get the
length of from. Anyway, since we always call this function with a
string in which there is at most one replacement to perform, there is
not so many repetitions in our use case. On the other hand we may want
to quit after the first replacement then, don’t we?
Now let’s have a look at the call site.
if (tokens[0] == "params")
{
std::string token_str(tokens[1].begin(), tokens[1].end());
replace(token_str, "${param}", "0");
replace(token_str, "${tag}", "123");
replace(token_str, "${id}", "foobar");
replace
(token_str, "${line_count}", std::to_string(line_count).c_str());
tokens[1] = std::string_view(token_str.c_str(), token_str.size());
concatenate_tokens(result, tokens);
++line_count;
}
In the last post we have seen how expensive the repeated creation of a
temporary std::string can be, so maybe we should move token_str
outside the loop and reuse it here; this would save us some
allocations. There is also an std::string created by
std::to_string but given the range of line_count I think we can
expect the result to benefit from the small string optimization, thus
avoiding an allocation.
Apart from that, we are calling replace four times, once for each
substitution. As we saw above, each call will scan token_str in
full, even though we don’t need it here. Also, the replaced parts will
be scanned again by subsequent calls, which seems useless in our case
since there is no placeholder in the replacements. Maybe we could scan
the string once, trying to match the placeholders along the way?
Batch replace
Edit 2023-03-23: From the first batch of comments I understand that I have been a bit sloppy here, so I feel obliged to be more explicit about the intent. The point of this section is that we can get better performance by designing an algorithm specifically for our use case and our inputs. The sub-point is that it has a cost (maintenance, code readability, etc.).
The function described below is not a good general string-replacement function. Moreover, even for our use case, it is not the most efficient either, as I tried to keep something simple for the post. Yet, the following performance measurements show an improvement over the initial implementation. Thus the point above.
Yes, the implementation could have been more efficient. Yes, the signature is bad. Yes, there are other string-replacements functions in the literature (in which case you may want to use an existing implementation, see the discussion about third-parties in the second part below).
Thanks to the first commenters for pointing these issues :) – End of edit.
Following the observations listed above, we are going to implement a
replace function that can do many substitutions on a single
scan. The function looks like this:
void replace
(std::string& s, const char* const * from, const char* const* to,
std::size_t n)
{
const char separator = from[0][0];
std::string::size_type pos = s.find_first_of(separator);
while (pos != std::string::npos)
{
bool found = false;
for (std::size_t i = 0; (i != n) && !found; ++i)
{
const size_t from_size = std::strlen(from[i]);
if (std::strncmp(s.data() + pos, from[i], from_size) == 0)
{
s.replace(pos, from_size, to[i]);
found = true;
pos =
s.find_first_of(separator, pos + std::strlen(to[i]));
}
}
if (!found)
pos = s.find_first_of(separator, pos + 1);
}
}
The function requires four arguments. The first one is the string in
which the replacements must be done. These replacements are done
inplace so the argument is passed by reference. The second argument is
an array of C-strings, listing the placeholders to be replaced. The
third argument is another array of C-strings, listing the
replacements, one for each entry of from. Finally, the fourth
argument is the number of entries in from, and thus also in
to. The function expects that all placeholders begin with the same
character; this character is copied in separator. Then the separator
is searched in the string. As long as a separator is found, the
function repeats the following steps. First he function loops over the
entries in from until a matching placeholder is found. If a match is
found, the replacement is done, then the search for a separator
continues in the part of the string following the inserted
replacement. Otherwise, if no match is found, the search resumes on
the first character following the separator.
Note that we have not implemented a way to stop if all placeholders in
from have been replaced once.
On the call site, it makes the call a bit more complex as we have to prepare the tables for the placeholders and their replacements.
if (tokens[0] == "params")
{
const char* const placeholders[] =
{
"${param}",
"${tag}",
"${id}",
"${line_count}"
};
constexpr std::size_t n = std::size(placeholders);
const std::string line_count_string = std::to_string(line_count);
const char* const replacements[] =
{
"0",
"123",
"foobar",
line_count_string.c_str()
};
static_assert(std::size(replacements) == n);
std::string token_str(tokens[1].begin(), tokens[1].end());
replace(token_str, placeholders, replacements, n);
tokens[1] = std::string_view(token_str.c_str(), token_str.size());
concatenate_tokens(result, tokens);
++line_count;
}
The placeholders are listed in the placeholders array, then we keep
track of their count in variable n. The corresponding replacements
are listed in the replacements array. For dynamic replacements
(i.e. the count of processed lines in our case), we have to build the
corresponding string beforehand, then to insert it in the array. We
also ensure at compile-time that the number of elements in
replacements matches the count in placeholders. The remaining of
the program stays the same: we create a temporary string for the
substitution, initialized with the input, then we call the replace
function, and finally we put the transformed string in the final
result string.
This is a bit more complex than the changes we did in the previous posts. Let’s see how it impacts the processing times:
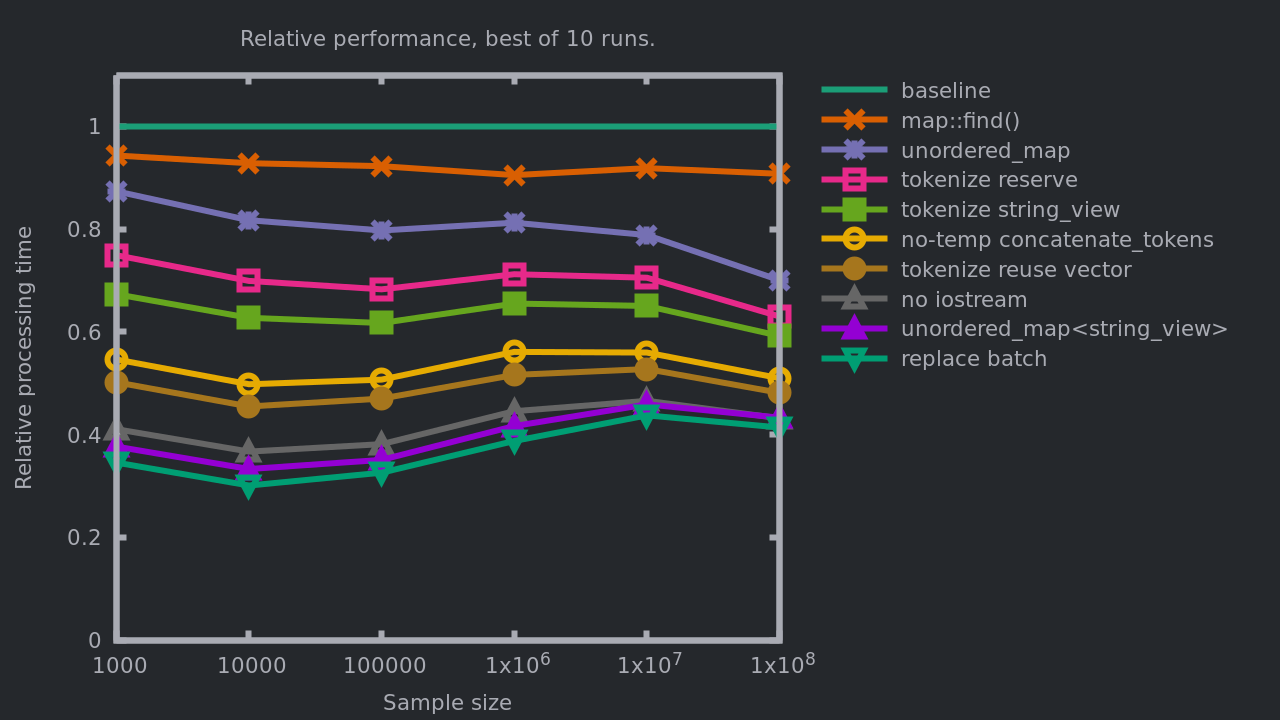
The performance gain compared with the previous implementation is in the range of 4 to 10%. Compared with the baseline, we are reaching 56 to 70%.
By implementing a task-tailored algorithm we are able to adapt the code to our specific needs. The old code was an inefficient solution for our problem, because it was a solution for a larger problem: replacing multiple occurrences of tokens and supporting the insertion of new tokens in the replacements. The new code describes our needs better and does barely more than needed.
In comparison with the gain we got in the previous posts, the
improvements here may seem quite low, especially regarding the effort
put into the code. Unfortunately there is no other way: Once all the
easy improvements are done, each extra percent of performance is going
to cost quite a lot of development time. Here the function could be
improved further but since the params records occur only in 20% of
the inputs, we are not going to reduce the processing time so much.
Let’s check the output of perf:
- 26% in
std::unordered_map<std::string_view, std::string_view>::operator[]. - 24% in
std::unordered_map<std::string_view, std::string_view>::find. - 9% in
tokenize. - 8% in
replace. - 5% in
concatenate_tokens.
It seems nice. We have improved all functions appearing in our top bottlenecks and our program is now at least twice as fast, sometimes up to three times faster!
Beyond std::unordered_map
Even though we made our program up to three times faster, most of the
processing time occurs in the management of an
std::unordered_map. Up to this point we have improved our program
under the constraints of staying in the limits of the standard
library. But what if we lift this constraint?
While std::unordered_map is a valid implementation of a
general-purpose hash table, we must take into account the huge amount
of work done in the recent years in the domain of hash tables. There
are indeed many maps out there and many are better than the one from
the standard library on different aspects. I would suggest the
excellent Comprehensive C++ Hashmap Benchmarks
2022 by
Martin Leitner-Ankerl for an overview of the alternatives.
Introducing a third-party dependency in a non-toy project must be done carefully. First of all, a third party, in any program, has a maintenance cost: Tracking, applying, and testing updates; maintaining and upstreaming patches; handling dependency conflicts between many libraries…
Secondly, if you pull a dependency from the Internet, among other problems, you take the risk of your project suddenly not compiling because the API of the dependency has changed, or worse: the package has been removed (see the story of npm’s left-pad package for example). But even if the package is not removed, there is the risk of an exploit by pulling malicious code from packages or their dependencies (a.k.a. supply-chain attacks). To mitigate these problems you may want to manage the package repository internally and to pin the version of your dependencies.
In the specific case of hash tables, we must also consider that if another third-party interacts publicly with a map, then there is a good chance that it will be one from the standard library. We will then have to manage many kinds of maps in our programs, maybe converting from one to another from time to time.
Finally, more often than not, non-standard maps do not comply with the restrictions imposed by the C++ standard. In particular, many implementations use open addressing which prevents reference stability (i.e. inserting or erasing an element in the table may change the address of unrelated elements). Worse, since they are not standardized, there is no guarantee that they would maintain all observable behaviors from one version to the other.
That being said, assuming we are okay with the above constraints,
let’s see if we can get something from another hash table
implementation. For our pet project I picked
tsl::robin_map, not because
it is the best or something, but just because I had good results with
it in a previous project. If it was not for the exercise, an actual
benchmark of the alternatives should have been done.
A good point for tsl::robin_map is that it has the same interface
than std::unordered_map, so using it is quite straighforward:
@@ -3,8 +3,9 @@
#include "replace.hpp"
#include "tokenize.hpp"
+#include <tsl/robin_map.h>
+
#include <algorithm>
-#include <unordered_map>
static void concatenate_tokens
(std::string& result, const std::vector<std::string_view>& tokens)
@@ -43,8 +44,7 @@
result.reserve(in.size());
std::uint64_t line_count = 0;
using entry_map =
- std::unordered_map<std::string_view, std::string_view>;
+ tsl::robin_map<std::string_view, std::string_view>;
That’s all we needed to flatten our performance curve:
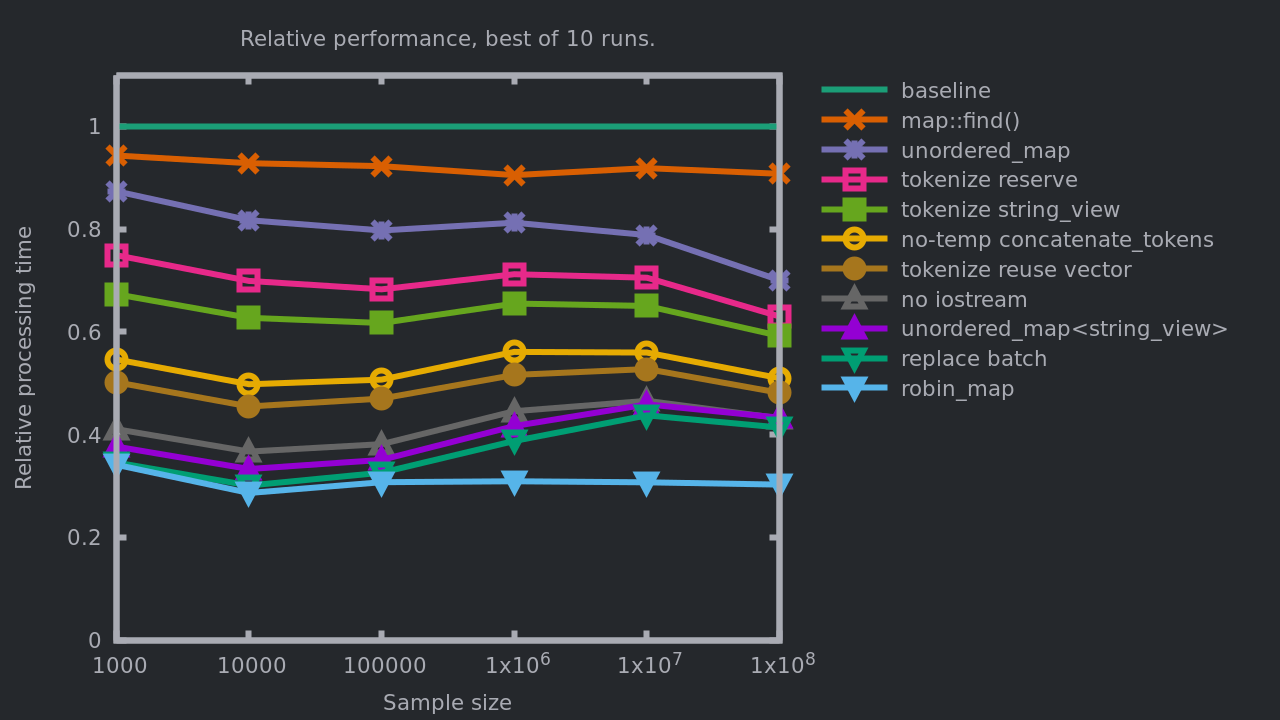
Thanks to tsl::robin_map the bump we had after 100'000 lines has
disappeared. This is a gain of 66 to 71% relatively to the baseline
(three times faster everytime!), and up to 30% faster than the
previous implementation.
It’s time to come back to our summary table:
| Input lines | Processing time | Throughput |
|---|---|---|
| 10 (~200B) | ||
| 100 (~2KB) | ||
| 1000 (~20KB) | ||
| 10’000 (~200KB) | ||
| 100’000 (~2MB) | ||
| 1’000’000 (~22MB) | ||
| 10’000’000 (~225MB) | ||
| 100’000’000 (~2.6GB) |
We find again in this table the improvements measured previously. Below is a graph showing how each change so far has impacted the throughput.
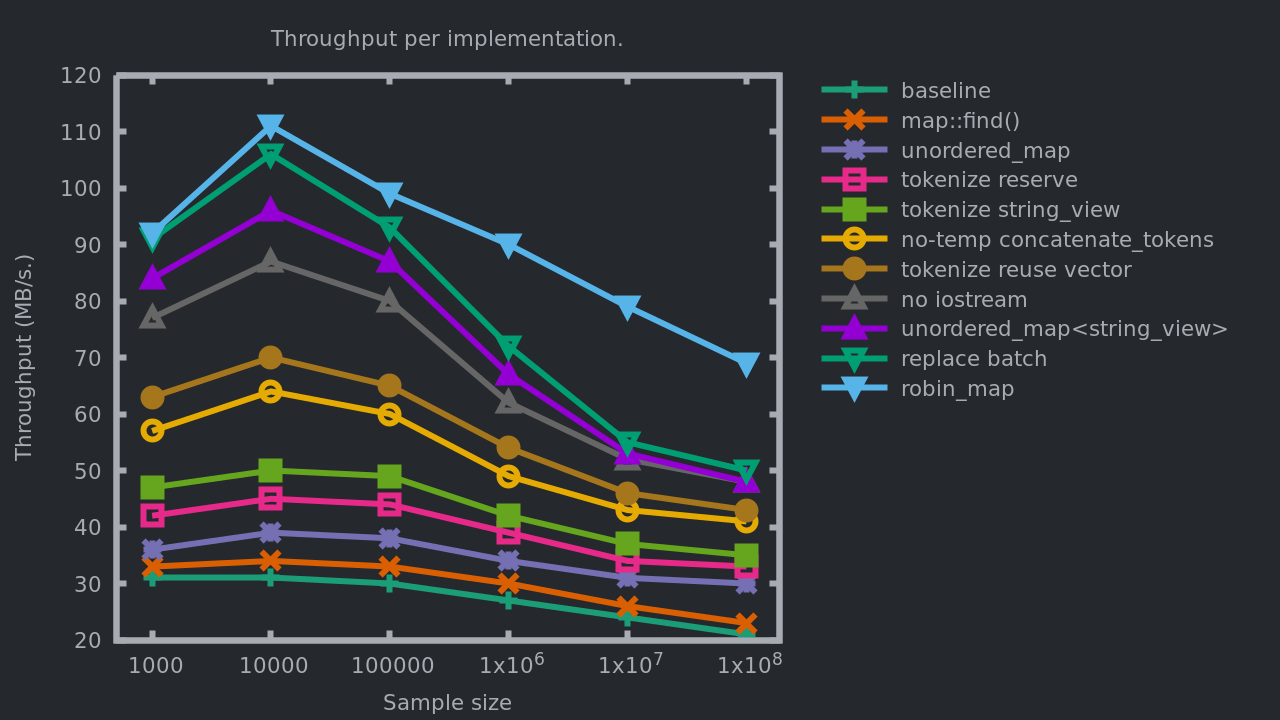
Interestingly, we can observe that the range covered by the throughput measures has increased greatly. While the initial implementation was quick to reach its maximum, we are now very much efficient for the here-optimal size of 10'000 lines, then we slowly pay the cost of accessing more and more RAM as the input size increases. In a sense, it means that the initial implementation was less impacted by the input size than by the micro details of memory allocations, string copies, map layouts, etc. The last implementation, on the other hand, cannot maintain its throughput as the input size increases, showing that it becomes limited by the memory bandwidth. It can certainly be improved further though.
Closing thoughts
During these five posts we applied a series of small changes to a program initially written in very straightforward and idiomatic C++, in an attempt to make this program more efficient, and to learn something along the way. So let’s recap what we have learnt.
The first takeaway would be to forget about std::map. If you need an
associative array, a dictionary, start with std::unordered_map.
The second point would be to allocate upfront and to re-use
dynamically allocated resources. Ideally, an API with a function
returning an std::vector, an std::string, or anything that could
allocate, should be also available with a signature accepting an
output argument.
Third thing to remember: string copies are subtly expensive. Try to
work as much as you can on the original string. Use std::string_view
whenever possible.
All these points were very easy to integrate in our program, and barely changed its readability. Moreover, it would have been even easier to apply these rules from the beginning.
The next point is a bit more difficult to apply as it requires a good
knowledge of the scope in which the program is used: Consider
task-tailored algorithms. By switching from our general replace
function to a function much closer to our specific use case, we made
our program faster.
Finally, if you agree to manage third party dependencies, you can get even better performance by switching to containers and algorithms from another library.
By applying these rules by default your programs will be more efficient from the start, then you won’t have to purchase more and more powerful computers with an always growing amount of RAM. Also, don’t forget to benchmark your programs, know your bottlenecks, observe how they behave with different inputs. Maybe you won’t need to optimize immediately, but by the time you will have to, you will know where to look.
Optimization as an afterthough is harder than necessary :)