Ce post a été publié sur LinuxFr.org. Vous pouvez le lire là bas, ainsi que les commentaires associés
Bonjour ’nal,
Un petit exercice d’algorithmique m’a récemment poussé à regarder en détail l’impact de différentes approches sur les performances et à remettre en question des connaissances que je croyais solides. Laisse-moi te raconter ce voyage.
Pour être en bonne santé, exercez-vous régulièrement
J’aime bien pratiquer des exercices de programmation sur des sites tels que CodinGame ou CodeSignal. Si tu ne connais pas, ces sites proposent un petit IDE en ligne et divers problèmes d’algorithmiques avec jeux de tests associés. Le jeu consiste à fournir dans l’éditeur en ligne un programme pour résoudre le problème donné ; l’implémentation se faisant dans le langage de ton choix. La plate-forme permet de lancer la solution sur les jeux de tests pour la valider.
Selon son profil on utilisera le service dans l’optique d’écrire le programme le plus court, ou le plus efficace, ou simplement un programme qui fonctionne. Pour moi c’est un peu un coding dojo : un lieu ou pratiquer et où se comparer aux autres pour apprendre et s’améliorer.
En particulier, lors d’une séance sur CodeSignal je me suis laissé allé à me comparer à la meilleure solution d’après les votants : pour chaque exercice j’implémente une solution d’une manière assez immédiate, un peu comme ça me vient, puis quand la solution est validée je regarde celles des autres. J’essaye de trouver leurs points forts, les miens, et je nous critique. Comme je fais les exercices en C++ je ne me compare qu’à la meilleure solution dans ce langage.
Présentation de l’exercice
Étant donné une matrice d’entiers, l’exercice consiste à calculer la somme des nombres qui ne sont pas sous un zéro. Par exemple, pour
0, 2, 3
1, 0, 4
5, 6, 7
Le résultat attendu est 2 + 3 + 4 + 7 = 16. Le 1, le 5 et le 6 ne sont pas comptés car il y a un zéro plus haut dans la colonne.
La matrice est représentée en row-major, c’est-à-dire par une table de tables où chaque sous table représente une ligne de la matrice. J’ai déjà rencontré des traitements de grandes matrices par le passé et ma première réflexion est « si je traite le problème par colonne comme le suggère l’énoncé je vais sauter d’une zone mémoire à une autre et avoir des perfs nases. Il vaut mieux traiter ce genre de matrice ligne par ligne. »
Je vais donc scanner les lignes pour additionner les valeurs. Un booléen associé à chaque colonne me dira si j’ai déjà rencontré un zéro dans cette colonne, auquel cas j’ignore la valeur.
En pratique je vais donc visiter des cases pour lesquelles je sais que les valeurs seront ignorées, que je n’aurais pas visitées en scannant par colonne, mais pour l’instant je pense que c’est pour le mieux.
De plus, peu avant de faire l’exercice j’avais visionné les présentations Parsing JSON Really Quickly: Lessons Learned (Daniel Lemire), Speed Is Found In The Minds of People (Andrei Alexandrescu) et Path Tracing Three Ways: A Study of C++ Style (Matt Godbolt) dans lesquelles les auteurs avaient amélioré les performances de manière remarquable en implémentant leurs algorithmes de manière branchless, c’est-à-dire sans conditions if qui amènent le prédicteur du processeur à faire des suppositions. Sans entrer dans les détails, il faut savoir qu’une prédiction a un coût d’annulation parfois plus grand que ce qui a été gagné par les prédictions justes. Un code sans conditions évite ce problème et se comporte de manière stable, mais il faut réussir à intégrer quelque chose correspondant à la condition dans les calculs.
Implémentation initiale
Assez de bla bla, allons dans le code. L’implémentation initiale (que tu peux retrouver dans ce dépôt sur GitHub) ressemble à cela :
int matrix_elements_sum_branchless(const std::vector<std::vector<int>>& matrix)
{
const int row_size(matrix[0].size());
std::vector<char> usable_column(row_size, 1);
int result(0);
for (const std::vector<int>& row : matrix)
for (int i(0); i != row_size; ++i)
{
const int v(row[i]);
result += v * usable_column[i];
usable_column[i] *= (v != 0);
}
return result;
}
Il n’y a pas beaucoup de lignes mais déjà beaucoup de questions, à commencer par « est-ce que c’est vraiment mieux qu’un scan de colonnes ? ». Regardons donc la solution la mieux notée sur CodeSignal.
int matrix_elements_sum_best_ratings(const std::vector<std::vector<int>>& m)
{
int r(0);
for (int j=0; j<(int)m[0].size(); j++)
for (int i=0; i<(int)m.size(); i++)
{
if (m[i][j]==0)
break;
r += m[i][j];
}
return r;
}
Bien, ça m’a l’air d’être un scan de colonnes justement ! Comparons les performances des deux implémentations à l’aide de Google Benchmark.
Le jugement
Pour les tests j’utilise une matrice de valeurs aléatoires, chaque cellule ayant une chance d’autant plus grande d’être zéro qu’elle est proche du bas de la matrice. Bien que l’énoncé indiquait une taille maximum de 10×10 pour la matrice, je teste aussi pour des tailles supérieures : 100×100, 1000×1000 et 10000×10000.
Run on (4 X 3100 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x2)
L1 Instruction 32 KiB (x2)
L2 Unified 256 KiB (x2)
L3 Unified 3072 KiB (x1)
-------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------
branchless/10 147 ns 147 ns 4624304
branchless/100 13613 ns 13612 ns 50630
branchless/1000 1363899 ns 1363210 ns 516
branchless/10000 134339389 ns 134330069 ns 5
best_ratings/10 40.5 ns 40.5 ns 17268039
best_ratings/100 1422 ns 1422 ns 485581
best_ratings/1000 49662 ns 49662 ns 14096
best_ratings/10000 3599890 ns 3599673 ns 204
Wow, la version la mieux notée est bien meilleure de la mienne ! Voyons si je peux améliorer ça. Déjà je me demande si l’implémentation branchless est vraiment mieux qu’une version avec branches. Comparons avec cette implémentation :
int matrix_elements_sum_branches(const std::vector<std::vector<int>>& matrix)
{
const int row_size(matrix[0].size());
std::vector<char> usable_column(row_size, 1);
int result(0);
for (const std::vector<int>& row : matrix)
for (int i(0); i != row_size; ++i)
if (usable_column[i])
{
const int v(row[i]);
if (v == 0)
usable_column[i] = 0;
else
result += v;
}
return result;
}
Nouveaux résultats :
-------------------------------------------------------------
Benchmark Time CPU Iterations
-------------------------------------------------------------
branchless/10 161 ns 161 ns 4315630
branchless/100 13757 ns 13757 ns 46364
branchless/1000 1352468 ns 1352375 ns 517
branchless/10000 134475422 ns 134475261 ns 5
branches/10 116 ns 116 ns 5764899
branches/100 7689 ns 7689 ns 84635
branches/1000 781502 ns 781443 ns 861
branches/10000 70365787 ns 70364814 ns 8
best_ratings/10 42.0 ns 42.0 ns 16691501
best_ratings/100 1091 ns 1091 ns 628554
best_ratings/1000 41888 ns 41886 ns 16697
best_ratings/10000 3454331 ns 3454125 ns 203
Mmmmh okay, donc la version branchless se comporte moins bien que la version avec branches. Décidémment c’est mal parti.
Des benchmarks et trop d’idées
Tiens, j’ai envie de tester avec un std::vector<bool> pour usable_column. Je doute que ça apporte un réel gain mais je me demande quel impact aurait l’implémentation bitset par rapport à la précédente. Ça commence à faire beaucoup de lignes dans l’output alors passons en mode graphique et profitons-en pour ajouter des tailles de matrices.
Apparemment mon ordinateur a un cache L1 de 32 ko, deux caches L2 de 256 ko et un cache L3 de 3072 ko. Cela signifie que sur des entiers de 32 bits les matrices en dessous de 64×64 tiennent dans un cache L1, puis dans L2 jusqu’à 128×128, puis L3 jusqu’à 512×512. Au delà il faudra aller chercher les données en RAM.
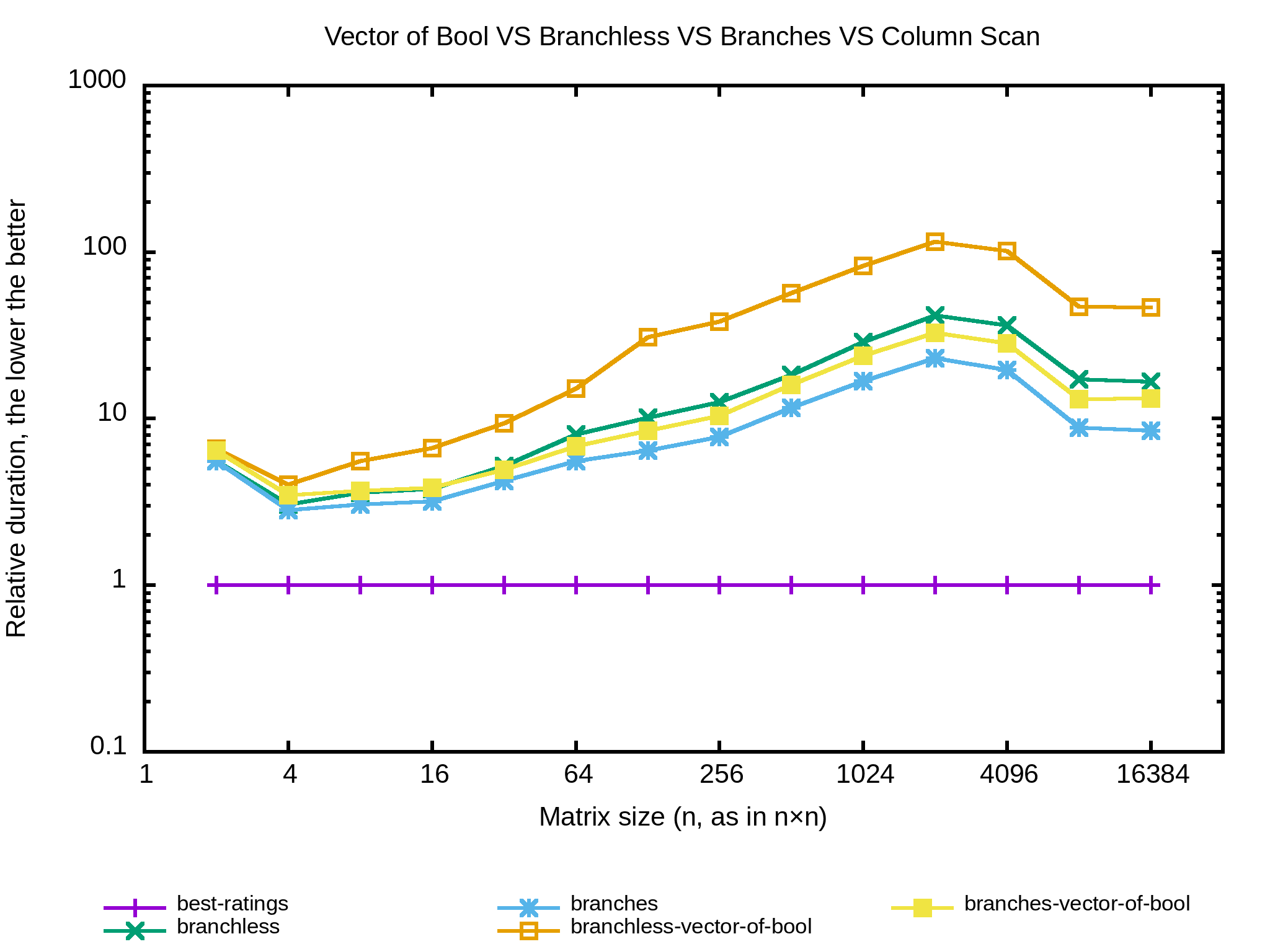
Bien, bien, bien… Les implémentations qui utilisent un std::vector<bool> sont moins efficaces que les originales, et dans tous les cas c’est pire que la version en colonnes.
Et si je stockais les indices de la première et la dernière colonne encore pertinentes ? Ainsi le nombre de colonnes scannées devrait réduire au fur et à mesure que l’on descend dans la matrice. Ça donne quelque chose comme ça :
int matrix_elements_sum_branches_range
(const std::vector<std::vector<int>>& matrix)
{
const int row_size(matrix[0].size());
std::vector<char> usable_column(row_size, 1);
int first(0);
int last(row_size);
int result(0);
for (const std::vector<int>& row : matrix)
{
for (; (first != last)
&& ((usable_column[first] == 0) || (row[first] == 0));
++first);
int last_non_zero(first);
for (int i(first); i != last; ++i)
if (usable_column[i])
{
const int v(row[i]);
if (v == 0)
usable_column[i] = 0;
else
{
result += v;
last_non_zero = i;
}
}
last = last_non_zero + 1;
}
return result;
}
Et le benchmark :
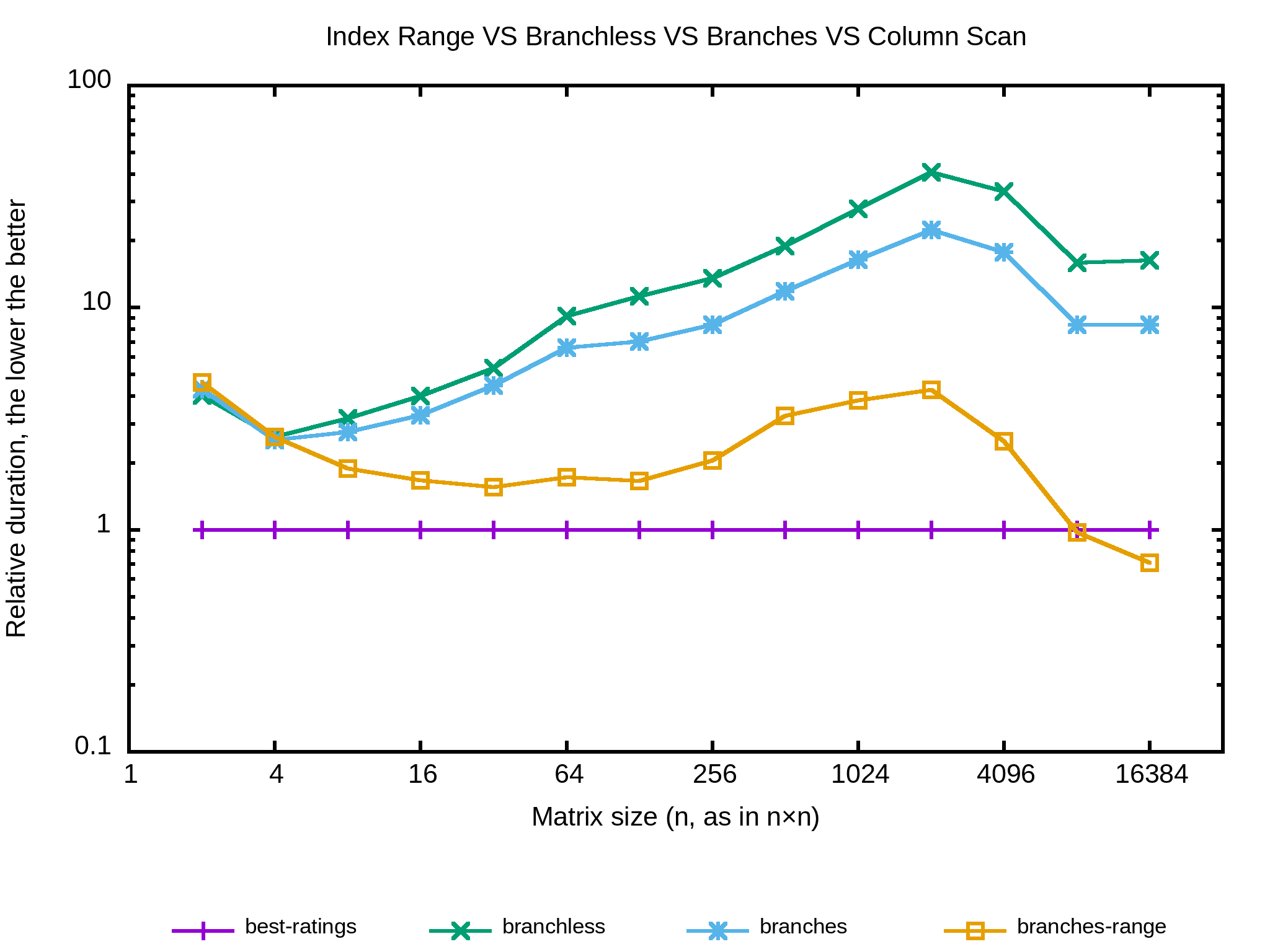
Ha-HA ! Ça coupe enfin la ligne de l’algo naïf. Est-ce qu’il y a moyen de faire mieux ? Déjà l’approche est un peu limite car l’intervalle des colonnes ne réduit efficacement que si les extrêmes contiennent des zéros assez haut. Je vais tenter de n’itérer que sur les colonnes dont je sais qu’elles sont encore pertinentes de façon à ce que l’ordre n’ait plus d’importance. usable_columns devient un vecteur d’indices de colonnes à traiter duquel je supprime les indices à chaque fois que je rencontre un zéro.
int matrix_elements_sum_indices(const std::vector<std::vector<int>>& matrix)
{
const int row_size(matrix[0].size());
std::vector<int> usable_columns(row_size);
const auto usable_columns_begin(usable_columns.begin());
auto usable_columns_end(usable_columns.end());
std::iota(usable_columns_begin, usable_columns_end, 0);
int result(0);
for (const std::vector<int>& row : matrix)
for (auto it(usable_columns_begin); it != usable_columns_end;)
{
const int i(*it);
const int v(row[i]);
if (v == 0)
{
--usable_columns_end;
*it = *usable_columns_end;
}
else
{
result += v;
++it;
}
}
return result;
}
Alors qu’est-ce que ça donne…
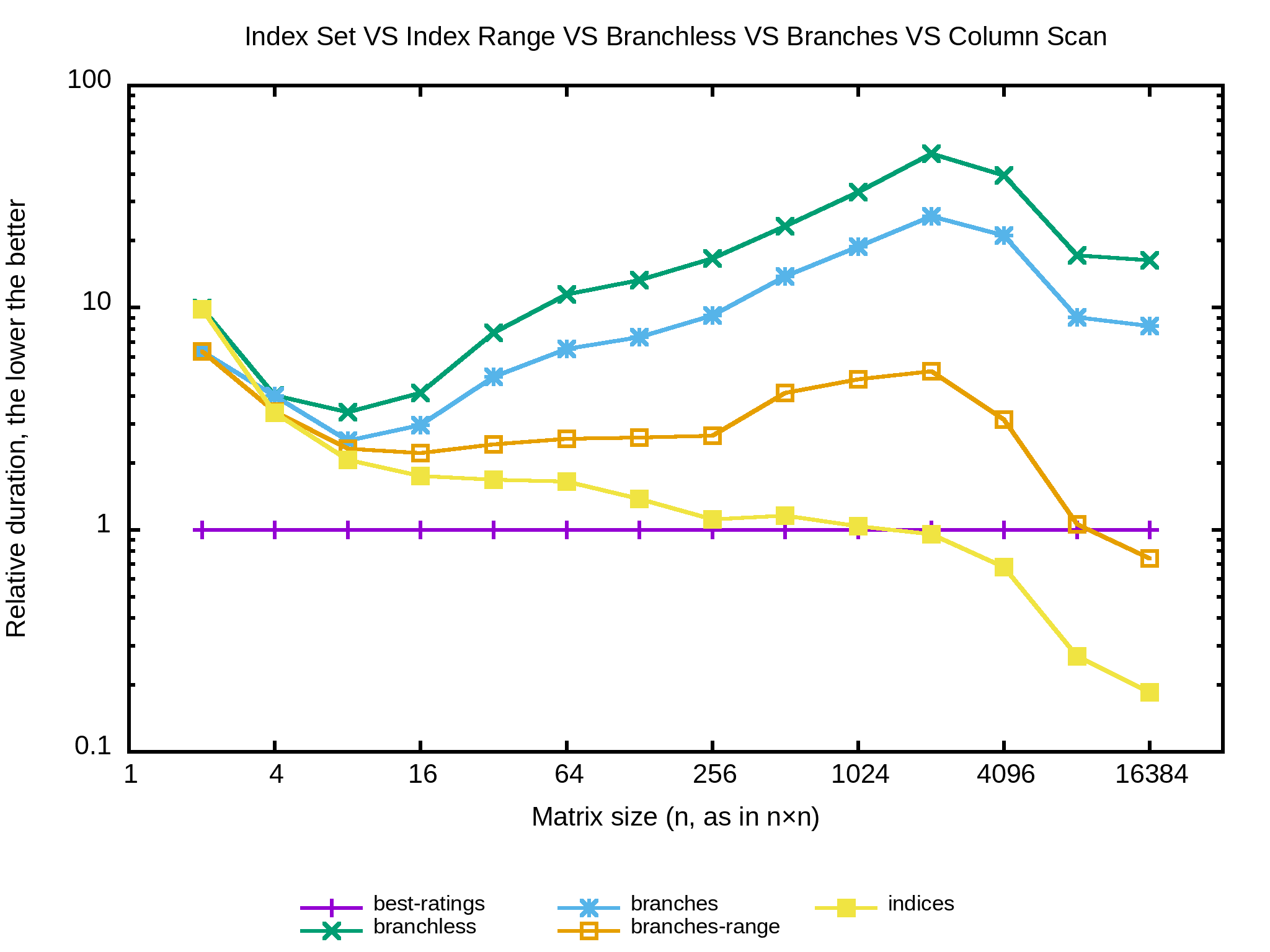
Wouhou ! Ça devient concret, dès 1024×1024 l’algorithme ci-dessus devient plus rapide que l’algo naïf. Quoi d’autre pour l’améliorer ?
La période sombre
Je n’aime pas trop la méthode utilisée pour retirer les indices de usable_columns : l’indice à supprimer est échangé avec le dernier de la liste puis on décrémente le pointeur de fin pour l’ignorer. Je m’attends à ce qu’après quelques itérations les indices soient complètement désordonnés et donc les accès mémoire complètement aléatoires. Est-ce que les performances seraient meilleures en passant un peu de temps à maintenir la liste triée ? Un seul moyen de le savoir :
int matrix_elements_sum_indices_sort
(const std::vector<std::vector<int>>& matrix)
{
const int row_size(matrix[0].size());
std::vector<int> usable_columns(row_size);
const auto usable_columns_begin(usable_columns.begin());
auto usable_columns_end(usable_columns.end());
std::iota(usable_columns_begin, usable_columns_end, 0);
int result(0);
for (const std::vector<int>& row : matrix)
{
for (auto it(usable_columns_begin); it != usable_columns_end;)
{
const int i(*it);
const int v(row[i]);
if (v == 0)
{
--usable_columns_end;
*it = *usable_columns_end;
}
else
{
result += v;
++it;
}
}
// Cette ligne en plus.
std::sort(usable_columns_begin, usable_columns_end);
}
return result;
}
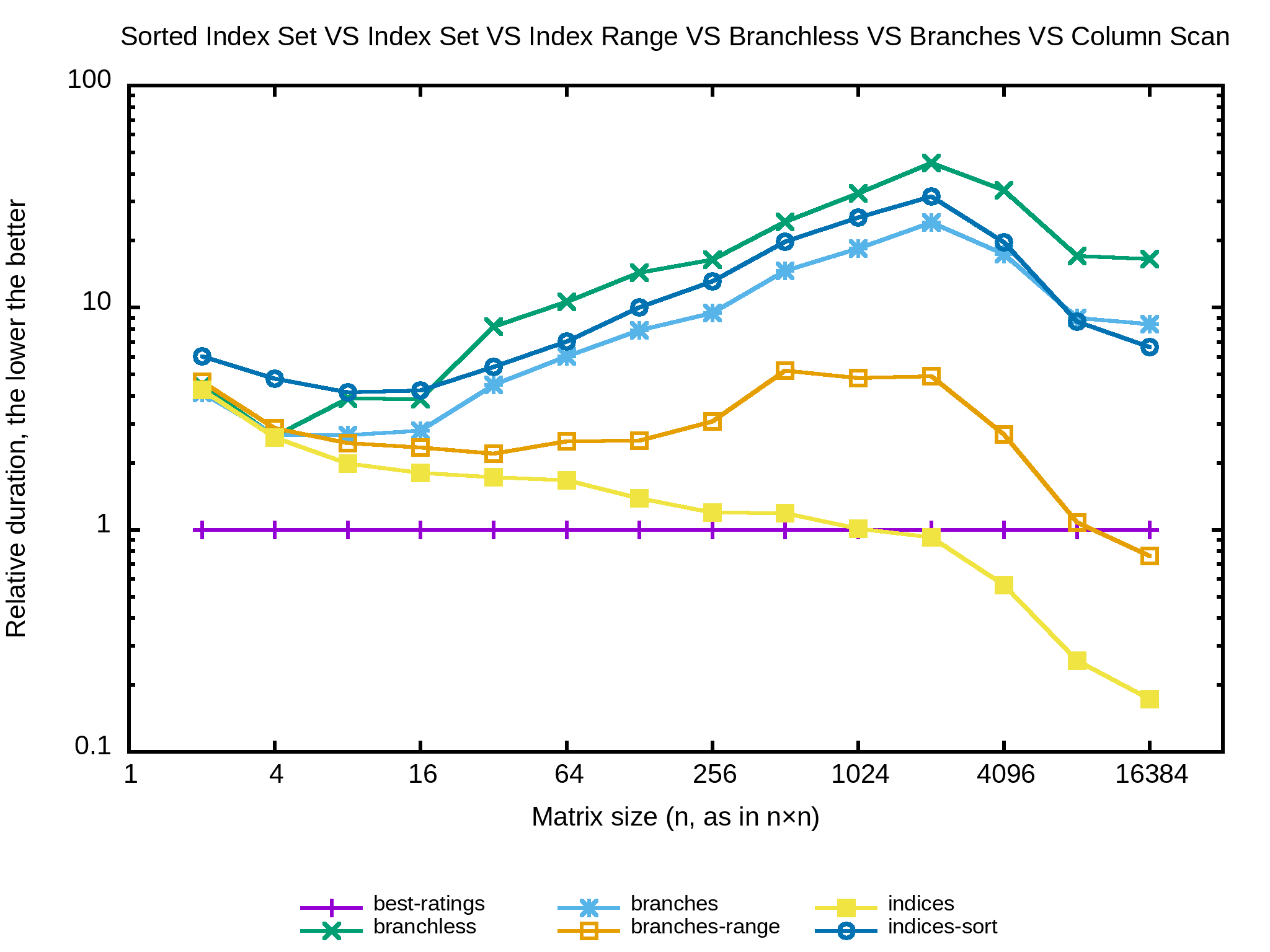
Non. Réponse égale non. Retrier les indices à chaque itération ne compense pas l’hypothétique perte de performances d’accès aléatoires en mémoire. Tentons la suppression de l’indice avec std::vector<>::erase(iterator) et puis une autre implémentation en stockant les indices dans un std::set et encore une autre dans std::unordered_set. Je n’y crois pas trop mais ça me semble important pour la complétude.
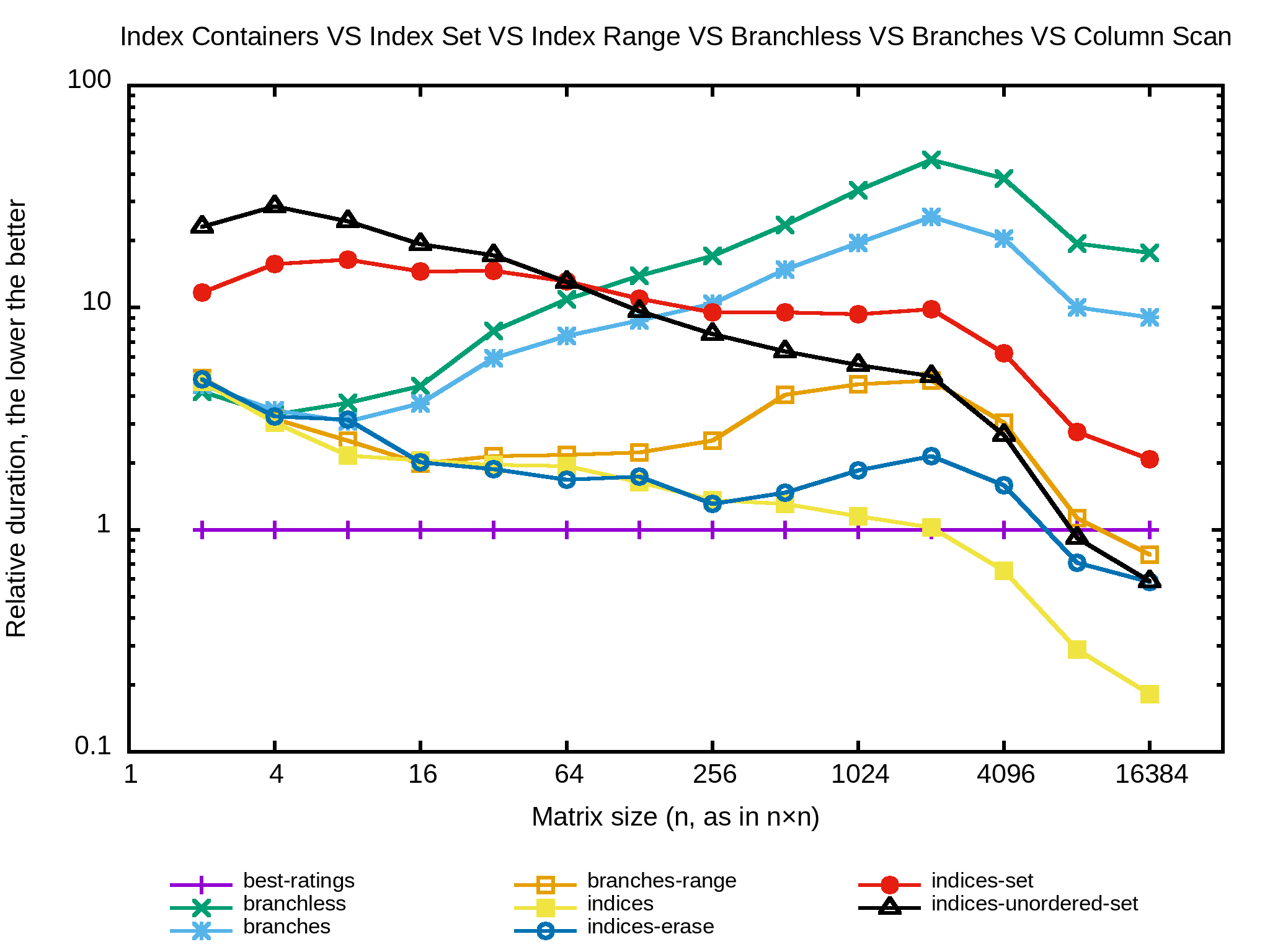
Sans surprise, il n’y a aucun gain ici. Le second meilleur, après l’algo naïf, reste celui qui conserve la liste d’indices dans un std::vector et qui échange les indices supprimés avec le dernier de la collection.
Et si l’algo retournait le résultat dès lors qu’il n’y a plus d’indices à traiter, c’est-à-dire la pratique du return early ? Tiens je vais essayer sur plusieurs des implémentations précédentes pour voir.
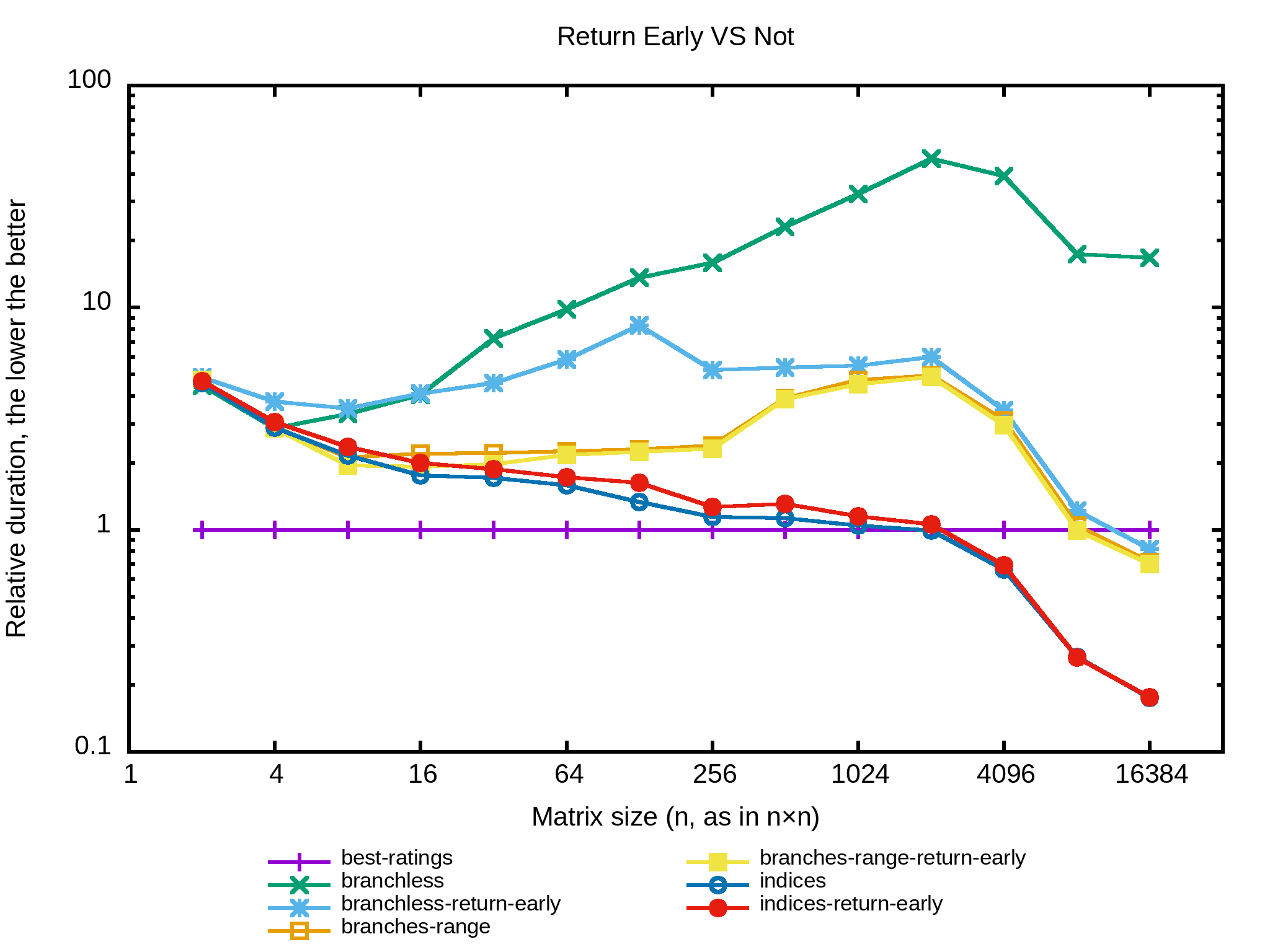
Bon, mauvaises piste. Ça fait partie du jeu de l’optimisation : dès fois on trouve et des fois on se perd. À part pour l’implémentation branchless il n’y a pas d’intérêt à quitter tôt. Cela dit c’est surprenant de voir que la version « indices » se comporte moins bien avec le return early. Est-ce le résultat de mauvaises prédictions du processeur ? Je ne saurais dire.
Continuons sur la version « indices ». La fonction commence par remplir un vecteur avec tous les indices de 1 à n par un appel de std::iota. Est-ce qu’on ne pourrait pas faire mieux en générant un tableau d’indices jusqu’à la taille maximum des matrices dès le début du programme puis initialiser la variable usable_columns à partir de ce tableau ? Nope, ça ne change rien. Crois-moi, j’ai testé.
Tiens, une autre approche classique de l’optimisation, je vais dérouler en partie la boucle la plus interne. L’implémentation commence à être un peu longue alors je vous invite à regarder le code sur GitHub. Il y a plusieurs implémentations :
indices_4_by_4parcourtusable_columnspar segments de 4 colonnes à la fois et swappe ces indices en branchless de manière à mettre ceux qui ont abouti à zéro à la fin de ce segment, puis les remplace par les valeurs à la fin d’usable_columns.indices_4_by_4_partitionfait la même chose mais utilisestd::partitionpour réordonner le segment.- et
indices_8_by_8_partitionfait de même sur un segment de 8 colonnes.
Et le benchmark :
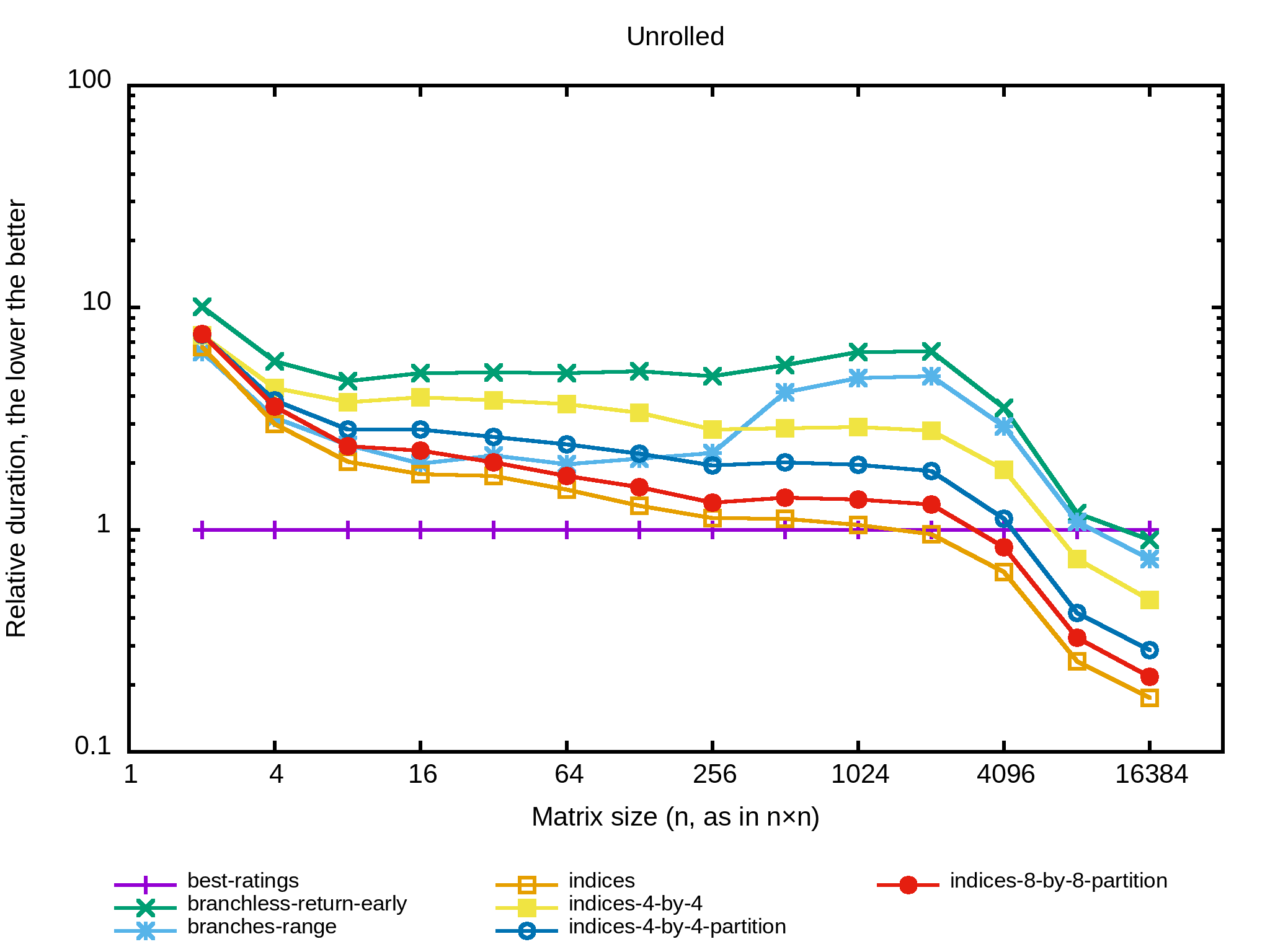
Bon, aucun succès à nouveau. Le compilateur se débrouille clairement mieux que moi pour optimiser la boucle, ce qui n’est pas vraiment surprenant.
Changement d’outils
Un peu à court d’idée je me demande ce que ça donnerait si la matrice était représentée en column-major plutôt que row-major. En d’autres termes, je me demande quel est l’impact de la structure de données sur les performances. Au niveau de l’algorithme ça serait assez direct:
int matrix_elements_sum_column_major(const std::vector<std::vector<int>>& m)
{
int r(0);
for (const std::vector<int>& column : m)
for (int v : column)
{
if (v == 0)
break;
r += v;
}
return r;
}
Et au niveau des performances :
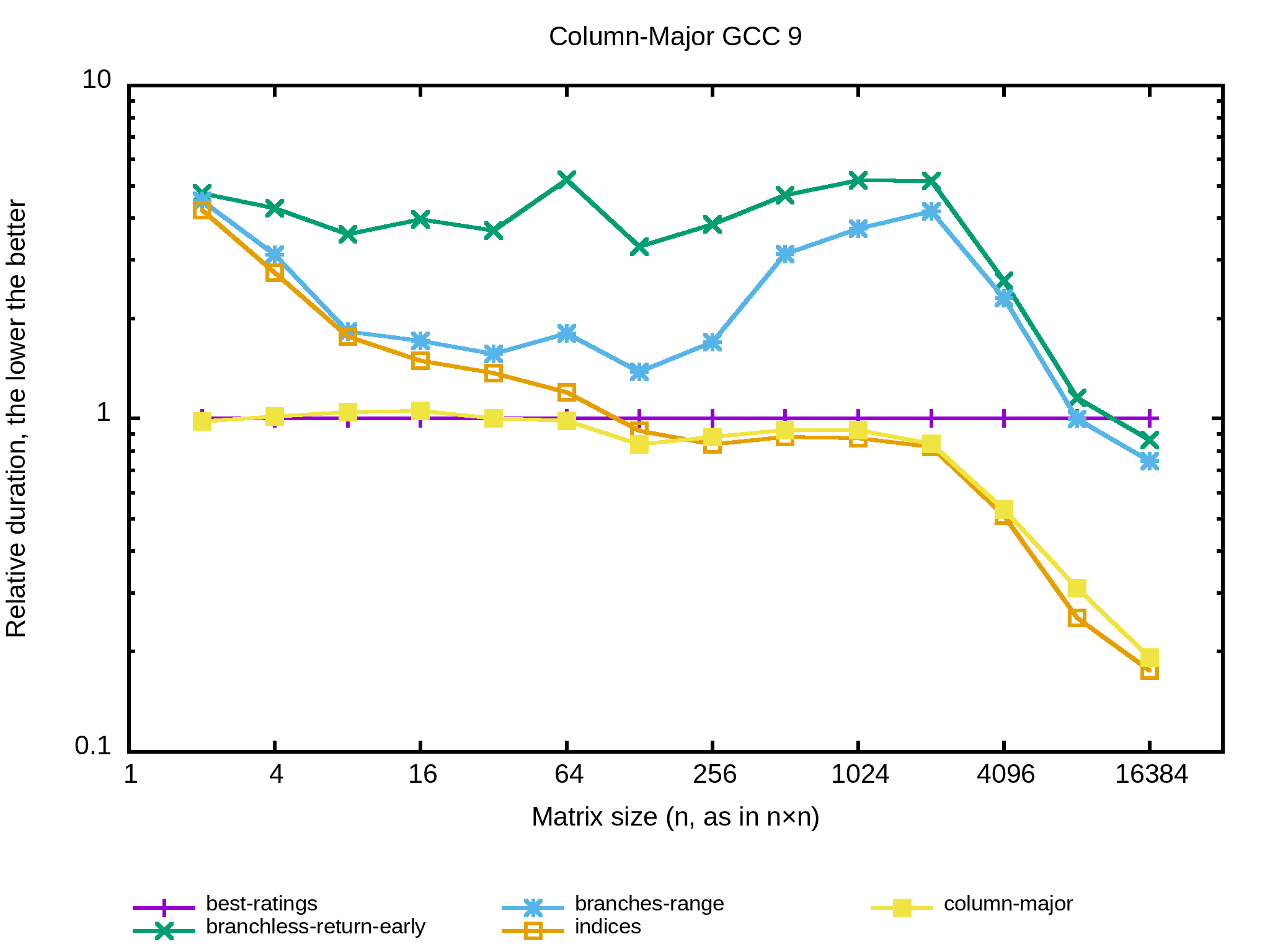
Intéressant, avec une structure de données en column-major les performances sont les mêmes que la meilleure combinaison des algos en row-major vus jusque-là, et l’implémentation est simplissime.
Est-ce qu’un changement de compilateur change aussi les performances relatives des implémentations précédentes ? Essayons avec Clang 9 :
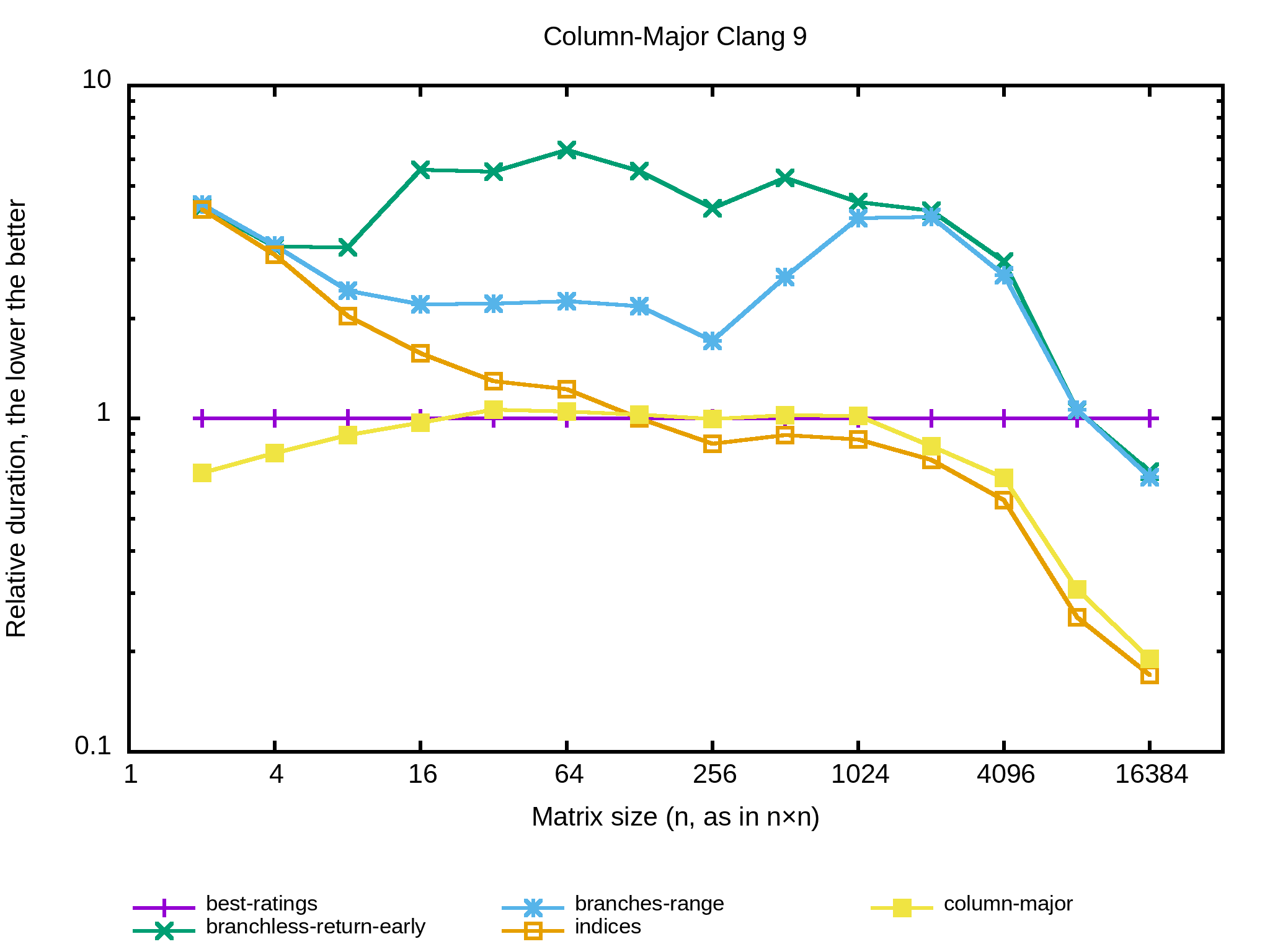
Ça ressemble pas mal aux résultats obtenus avec GCC 9, avec un clair gain pour la structure de données column-major pour les petites tailles. Par contre, cette structure de données perd face à indices en row-major des 256×256. C’est surprenant.
Allez pour finir comparons les performances relatives de Clang et GCC dans un seul graphe. Le programme est compilé avec les deux compilateurs puis lancé sur la seed 1234. Je ne prends que les meilleurs algorithmes vus précédemment :
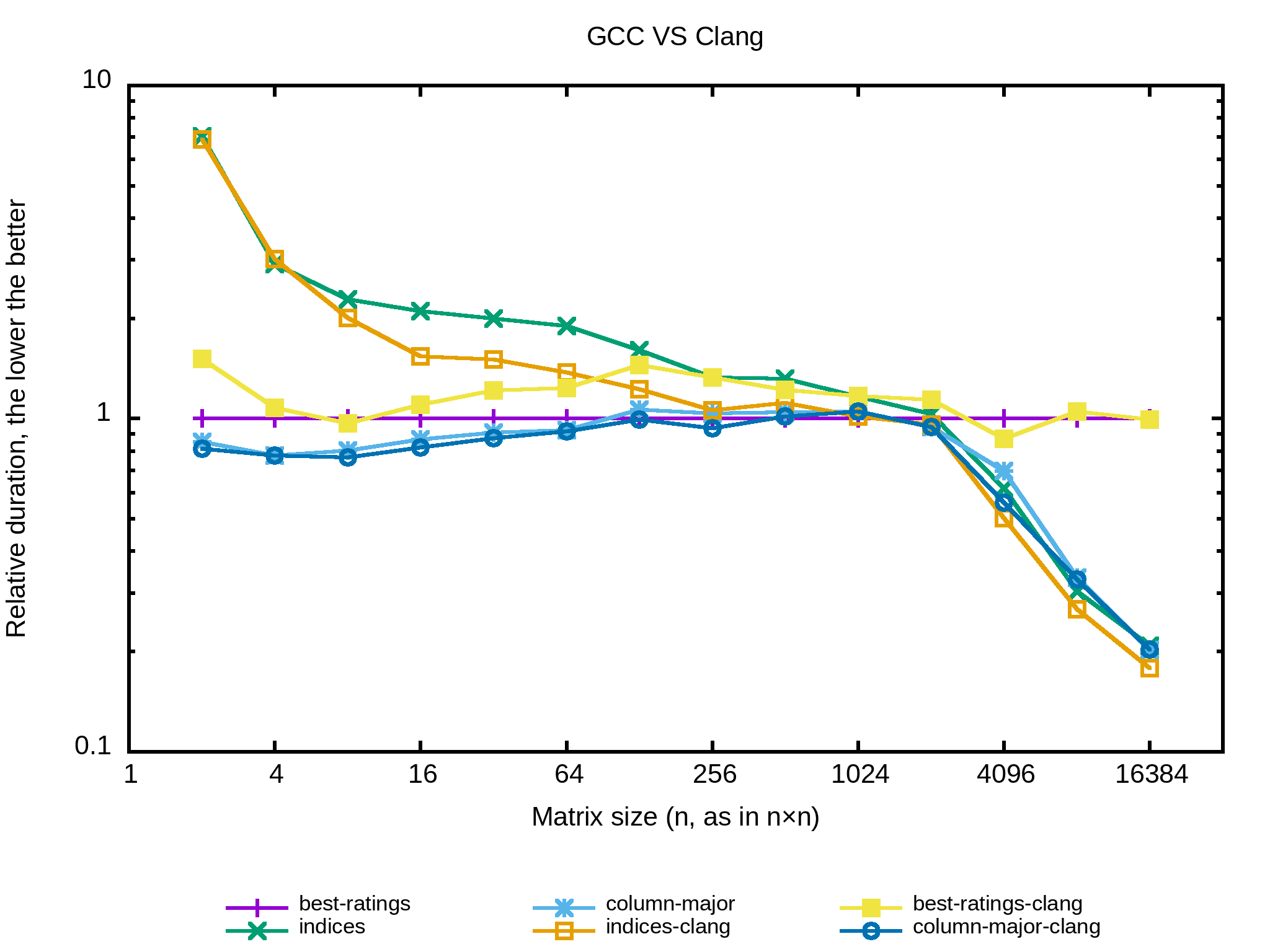
Globalement c’est assez semblable même si Clang se débrouille légèrement mieux sur la version indices et GCC l’emporte à peu de choses sur l’algorithme naïf. Sur la version column-major aucun deux compilateurs ne se démarque.
Il y a quatre ans j’avais effectué des benchmarks qui montraient une forte différence d’optimisations entre GCC et Clang . C’est agréable de voir que les performances des deux compilateurs sont maintenant plutôt proches.
Quand et quoi optimiser
Premature optimization is the root of all evil.
Il est coutume dans le monde des programmeurs d’accueillir par cette citation (amputée) toute tentative d’optimisation d’un code sans avoir d’abord montré son impact sur les performances. La version longue, moins souvent citée, ressemble à ça :
We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%. — Donald Knuth
Faut-il pour autant écrire les algorithmes les plus naïfs dès le départ comme pour prévenir toute sorte d’optimisation prématurée ? Eh bien ça dépend. L’algorithme naïf pour le problème considéré ici est performant tant que la matrice est très petite, puis s’écroule rapidement au fur et à mesure que les matrices traitées sont plus grandes. La question qu’il faut alors se poser est « Quel est l’ordre de grandeur des données que mon algo va réellement traiter ? » Autrement dit, est-ce qu’il y a absolument toutes sortes de tailles (ce n’est certainement pas le cas), est-ce que les matrices tiennent toujours dans le cache du processeur ?
Nous avons vu aussi que la structure de données elle-même a un fort impact sur les performances. En passant en column-major un algorithme natif se comporte aussi bien que les meilleurs cas de tous les autres de la version row-major. Ce qui amène à une autre question qui ouvre la porte à d’autres formes d’optimisations : ai-je la main sur la structure de données ? Comment puis-je la transformer pour simplifier mon implémentation et le travail du compilateur ?
En tant que développeur je pense qu’il est bon d’acquérir une certaine culture sur ce que peut faire le matériel qui fait tourner nos programmes ainsi que sur le coût relatif des traitements de nos algorithmes. Non pas pour optimiser tous les cas d’utilisations mais au moins pour ne pas surcharger de traitements inutiles des programmes déjà gourmands. Une sorte de preuve de bonne intention en quelque sorte.
Cette culture s’acquiert par la pratique ; c’est ce que nous apportent ces exercices de programmation. Notamment ici l’approche que je croyais solide (row-major -> scan par ligne) était complètement à la rue sur les petites tailles. On voit alors l’intérêt de pouvoir faire tenir les données dans le cache du processeur. De plus les versions branchless étaient moins performantes que les équivalents branchful (peut-être est-ce juste un manque de savoir faire pour le coup). Ce fut aussi l’occasion de tester un paquet d’implémentations et de constater, à nouveau, l’incroyable travail d’optimisation que font les compilateurs avec notre code.
Finalement ce petit exercice de programmation a amené beaucoup de questions et des réponses parfois surprenantes. J’ai appris des choses donc je pense que ça valait le coup. Nous verrons si les exercices suivants sont aussi enrichissants !