Table of contents
This is the third post in the series about effortless performance improvements in C++. Check the first post to get the full story!
Last
time
we switched from std::map to std::unordered_map and got 30%
performance improvements. After these changes we observed that the
tokenize function was a top hotspot, mostly due to
std::vector::push_back. How can we improve the performance of this
function?
What’s an std::vector anyway?
In short, std::vector is a dynamically allocated array whose
capacity increases as needed. Internally, this container manages a
dynamically allocated storage buffer where the items can be
stored. When the storage is full and a new item must be inserted, a
new (larger) buffer is allocated and the items are moved from the old
buffer to the new.
There is an std::vector::size() function to get the number of
elements stored in the vector, and std::vector::capacity() to get
the number of elements it can contain without having to
reallocate. Let’s unroll a small example to better understand what is
going on under the hood. Here int* m_data is the internal buffer in
a vector of ints.
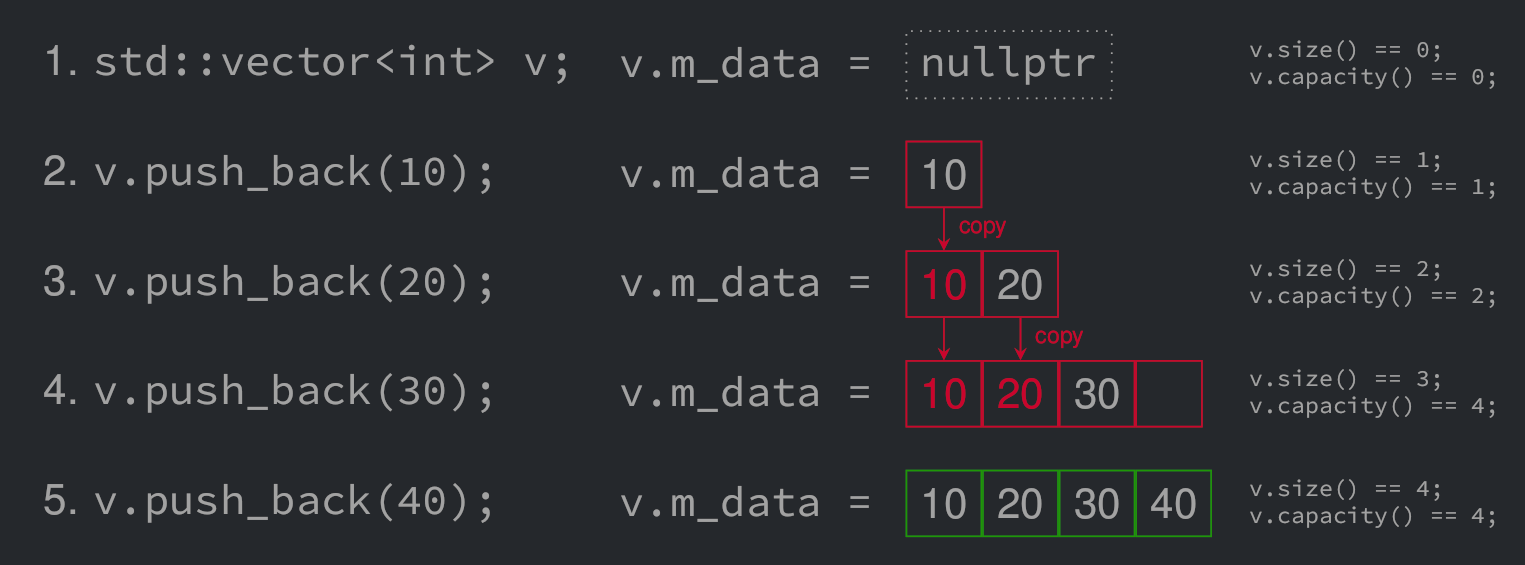
- Initially there is nothing in the vector:
m_data == nullptr,capacity() == 0, andsize() == 0. - When the first item is inserted,
m_datais assigned a dynamically allocated buffer of size 1, then the value 10 is stored in the buffer. - When the second value comes in, there is not enough room to store
it. A buffer of size 2 is allocated and the content of
m_datais transferred into it. Then the value 20 is stored in second position in the new buffer. The memory initially assigned tom_datais freed. - When the third value is inserted, there is again not enough room
to store it. A buffer of size 4 is allocated (assuming a growth
factor of 2) and the content of
m_datais transferred into it. Then the value 30 is stored in third position in the new buffer. The memory originally assigned tom_datais released. - Finally a fourth value is inserted. This time there is enough
room in
m_datato store the value so it is just appended in the buffer.
So here we have 4 values to push in the vector and it costs us 6 calls
to the memory allocator (3 malloc and 3 free) and 3 copies. If we
could allocate the memory upfront it would save us many
operations. Thankfully there is the API for it in std::vector in the
form of the std::vector::reserve. Let’s see how we can use it in the
previous example.
std::vector<int> v; // v is empty, m_data is nullptr.
v.reserve(4); // assign a buffer for 4 ints to m_data.
v.push_back(10); // append 10 in m_data; no allocation.
v.push_back(20); // append 20 in m_data; no allocation.
v.push_back(30); // append 30 in m_data; no allocation.
v.push_back(40); // append 40 in m_data; no allocation.
It’s a lot less work. Sounds promising, isn’t it?
tokenize with std::vector::reserve()
The result vector in our tokenize() function is used in a manneer
similar to the vector in the above section: we create the vector, then
we push a new entry for each token from the input. Additionally, the
cost of copying the data during reallocation is a bit higher since we
are transferring instances of std::string, not simple ints. We
are going to apply a very minor change in our function:
-3,6 +3,8
std::vector<std::string> tokenize(const std::string& s)
{
std::vector<std::string> result;
+ // Expect four fields or less in our input.
+ result.reserve(4);
std::string::size_type f = 0;
std::string::size_type p = s.find(':');
Let’s see how it changes the performance of our program.
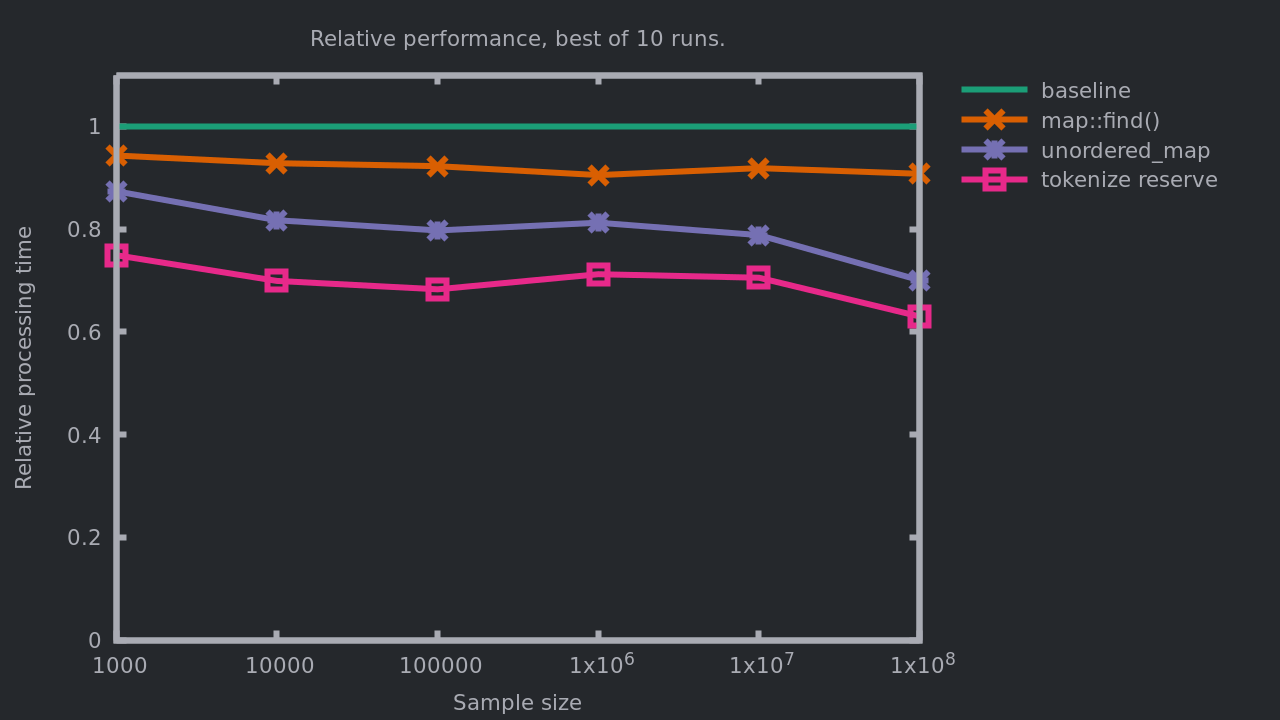
We are now saving up to 37% of the processing time relatively to the initial implementation, and between 10 to 15% relatively to the previous implementation! Does it change something to our bottlenecks?
- 18% in
std::unordered_map<std::string, std::string>::operator[]. - 14% in
std::unordered_map<std::string, std::string>::find. - 10% in
tokenize.- Mostly in
std::string(const std::string&)andstd::string::substr().
- Mostly in
- 7% in
replace.- With
std::string::findas the top offender.
- With
- 7% in
std::getline.
Even though we made tokenize faster, it is still consuming a good
share of the processing time by creating substrings from the input and
storing them in the result vector. Let’s see if we can do something
about it in part
4.